
Calculating odds is a science, and statisticians/analysts, who can do the job competently, receive good annual salaries (GBP 50k-80k; €60k-95k: Quantitative Analyst).
These jobs are paid so well because the results form the backbone of each bookmaker’s business. The better an analyst understands his job, the bigger the potential profit margins for the bookmaker. In order to make long-term profits, a good understanding of odds calculation is therefore also essential for any bettor.
Image: alphaspirit (Shutterstock)Probability of Football Match Results
Odds are based on the probability that a certain event occurs: for example a home win, a draw, or an away win in football games based on historical data. But what is the current probability of each of these outcomes and how are percentages computed? Also, from where does one get the data from?
The following diagram shows the distribution of results for the English Premier League for home win, draw, and away win during the last five complete seasons:

Looking at the graph, one can see that the distribution of results is rather similar for each year.
Without considering factors such as matches between strong or weak teams, teams under new management, rain affected games or anything else one can think of, fixtures in the English Premier League, according to the statistics, show on average 24.46% of all games were drawn, 27.35% ended in an away win and 48.16% were won by the home team:

Only twice (of 15) did results fall outside of ± 2% residual from the average figures, being drawn games in 2005/2006 (-4.2%) and away wins in 2009/2010 (-3.4%):

Comparison of the expected results with observations
Now, it is time to compare the expected results (based on the average results of 5 years) with the observed results of the current 2010/2011 season up to 19 February 2011:

There are quite large differences from the expected values (averages or means) to the observed results (actual results for 2010/2011) in both the drawn matches and away wins categories. However, I am pretty sure that by the end of the season, the figures will adjust themselves more in line with the 5-year average figures and that the differences showing now can be explained by having compared only two-thirds of the current season with the average results of a full-year. However, this indicates that there is an uneven distribution of home wins, draws and away wins at different times over the season, which should balance out by the close.
So, if the odds of a single match are calculated, this seasonal effect must be considered, but for this article and for your general understanding, I shall not complicate matters by touching on it further.
Mean (average value), Errors and Residuals (relative and absolute deviation)
For those of you with difficulties understanding what arithmetic mean and errors/ residuals are, herewith a few additional explanations with examples:
- Arithmetic Mean
The arithmetic mean, often referred to as simply the mean or average when the context is clear, is a method to derive the central tendency of a sample. In probability theory, the mean is also called expected value (or expectation, or mathematical expectation, or the first moment).
The mean (average value) is a known value and can therefore be used as an expectancy value.
Simply speaking, one can use the mean to predict future events (e.g. the distribution of football results) quite accurately.
Example using the 5-Year English Premier League table above for home games:
(50.53% + 47.89% + 46.32% + 45.29% +50.79%) divided by 5 = 48.16% (= mean/ average)
Therefore, it “is expected” that the 2010/2011 season will produce 48.16% home wins. - Errors and Residuals (relative and absolute deviation)
Statistical errors and residuals are two closely related and easily confused measures of the deviation.
The error of a sample (e.g. observed football results for a certain period of time) is the ‘relative’ deviation from the function value (mean), while the residual is the difference (absolute deviation) between the sample and the function value (mean).For example, the RESIDUAL (absolute deviation) for home wins during 2005/2006:
50.53% (2005/2006 home wins) minus 48.16% (average value for 5-years) = 2.37% (= residual)For example, the ERROR (relative deviation) for home wins during 2005/2006:
2.37% (residual) divided by 48.16% (mean) = 4.92% (= error)The error (relative deviation) is the proportional deviation between the observed value (the actual results) and the expectancy value (the mean/ average of all years). The error (relative deviation) puts residuals into relation to each other.

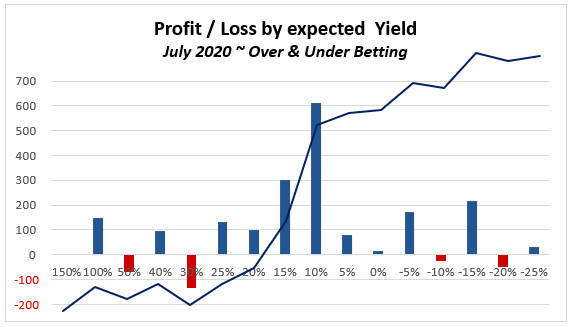

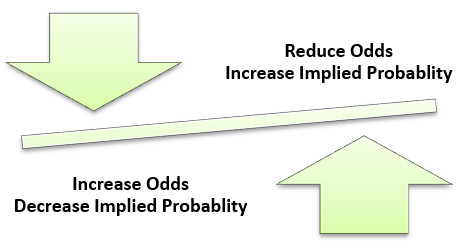


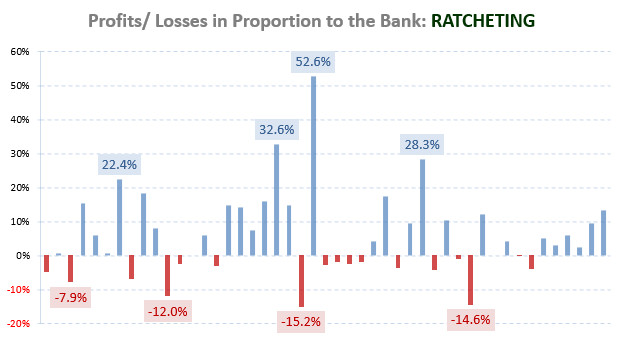

How do get form factor figure?
Hi Mathew,
Can you please be a little more specific – what exactly is it you are trying to figure out?
Hey. i wanna know how I can use probability to predict the putcomes of football bets. Mind showing me how?
Hi Derrick, we’ve got a course that teaches probabilities to predict outcomes in detail: The Science of Football Predictions
The course has already helped many people; so it will probably also be of great help to you. Good luck! 🙂
Hello
I have been using some data like
1. Average Home Team goals,
2. Avereage Home team conceeds
3. Average scored by Away Team
4. Average Conceedes by away Team
I also use:
1. Attacking rating
2. Defensive Rating
How can I combine these statistics to get me an idea of expected result.
I am aware that per chance things can change
Erny
Hi Erny,
I’ll have to think about that and add your question to the 1×2 course I have been planning to write for a long while, especially the attacking/ defensive rating… No idea, to be honest, because I don’t even know where I could get enough data from to analyse it properly.
Generally speaking, from a statistical perspective, football matches do not occur frequently enough. For example, looking at a single league such as the German Bundesliga with only 306 matches per season, a relevant sample size is never going to be large.
The plain truth is that any football league is simply not large enough to generate a significant amount of completed match statistics per season. This means that the standard deviation (margin of error) is always going to be relatively large…. and attacking/ defensive rating… it’s only the last few matches, isn’t it?
I probably wouldn’t burn my fingers with it.
If odds are 2.0 and 3.12 what is possible outcome
Hi Kelvin,
Odds and ‘possible outcomes’ are really connected. Bookmakers seldom price ‘true’ probabilities.
Here’s an article on this topic: How Bookmakers’ Odds Match Public Opinion
If you prefer videos, here are a few:
Over Under Clusters Cluster Tables – Calculate ‘Fair’ Odds
1X2 Home — Draw — Away: Expected Odds Calculation & Setting of Market Prices